Blog
The Truth About Online Data Quality: 30% of Survey Respondents Live on Pluto

Picture this: a client approaches you to run a brand awareness survey or a package testing study. You and your team do your due diligence designing the study, programming the survey, finding a sample vendor, and gathering the data.
Then, someone spots a problem. While analyzing the data, your team found a substantial percentage of respondents appeared to answer randomly, failing to give sensible responses to even the most basic questions.
Faced with having to toss 20 to 40 percent of your data, how would you feel about your project?
If the scenario above sounds scary, that’s because it is. In today’s online research environment, there are several threats to data quality and the validity of online research. Here, we shed some light on what these threats are and what to do about them.
What Do You Mean 30% of My Study Consists of Bogus Data?
Perhaps the best place to begin talking about online data quality is with offline data quality.
Although some challenges to online research are a product of the internet—fraud from international respondents, the threat of bots—others such as mischievous responding and participant inattention are as old as survey research itself.
As an example, consider the Add Health study. Add Health is a federally funded National Longitudinal Study of Adolescent to Adult Health that was conducted with a nationally representative sample of over 20,000 adolescents in the 1994-1995 school year and has had several follow up waves that continue to this day.
Expensive to conduct, ambitious in its aims, and overseen by talented experts, even Add Health was not immune from problems with data quality.
After collecting the original data, some researchers began probing the Add Health files and noticed some suspicious responses. For example, in one branch of the study, 19% of respondents reported being adopted. When researchers sought to confirm this fact during in-person interviews with each respondents’ parents, the parents contradicted these claims. Nearly all of the children were actually biological children.
In another striking example, researchers found that 99% of the 253 people who indicated that they had an artificial limb were, in fact, lying. It appears many respondents thought it would be funny to claim a medical status they did not have.
So, how do these issues translate to online research?
Well, within online panels, respondents are not immune from inattention or mischievous responding. Studies indicate that roughly 30% of panel respondents routinely fail simple attention check questions.
More alarmingly, online studies are susceptible to fraud and the threat of bots. Unfortunately, some online studies have been overrun with suspicious respondents from international sources, underscoring the threat of fraud. And, more than one online panel has had to confront concerns about automated survey responses. Thus, regardless of the exact source, the threat of gathering bogus data from online respondents is very real.
For more concrete evidence of the problem, consider some of the data from people who have failed CloudResearch’s patented SENTRY® vetting system. Among respondents who fail SENTRY’s most basic level of screening, 51.2% report working as a Petroleum Engineer (a rare job), and roughly the same percentage report living in New Salem, Indiana (population < 6,000).
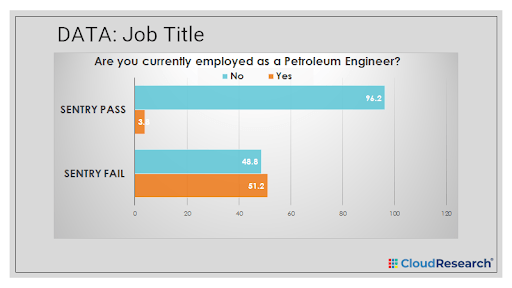
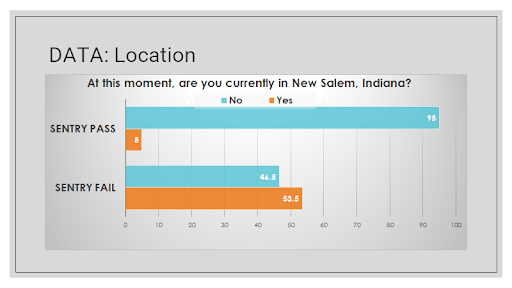
In other studies, people who fail SENTRY have led researchers to find illusory effects—the kind of effects that can lead to incorrect business decisions.
Most notably, following the onset of the COVID-19 pandemic, the CDC released a report that suggested 39% of Americans engaged in dangerous cleaning practices, including washing food with bleach, gargling or drinking household cleaner, and other acts that seemed unlikely on the scale of tens of millions of people.
When CloudResearch replicated this study, we found that very high-risk cleaning practices were almost exclusively reported by respondents who failed SENTRY. The gap in self-reported cleaning practices for people who passed and failed SENTRY was consistently around 20%.
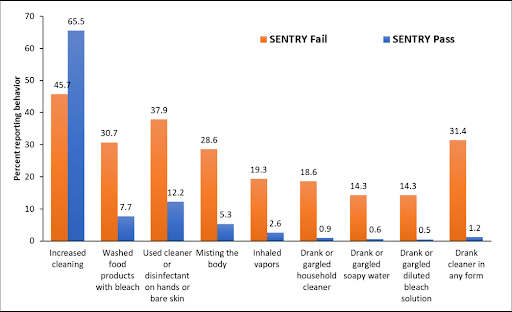
Failing to remove this sort of “noise” from your dataset can create problems for market researchers and businesses looking to make data-driven decisions. Unfortunately, it can also lead to professional embarrassment.
How to Catch Bad Data and Preserve the Validity of Online Research
If data quality in online studies is a concern, what can be done to address the issue and ensure the decisions you make are valid?
Given the various threats to online data quality—participant inattention, yea-saying, mischievous responding, international fraud, and bots—panel providers can institute things like a CAPTCHA for bot-detection, digital device fingerprinting for flagging fraud, and location-based tools for removing bad actors. While these tools can mitigate issues with data quality, they cannot completely solve them. Indeed, all of the bad data identified by our SENTRY tool above were gathered after basic technical checks performed by panel providers.
To bolster panel tools, individual researchers can implement things like attention checks within their surveys, a system for flagging suspicious IP addresses, and a process for evaluating the quality of open-ended responses. Each of these methods can help identify respondents a researcher may want to exclude from analyses. But these methods are reactive, waiting for participants to provide bad data in order to act.
Is there a more active way to prevent data quality issues?
As it turns out, there is. Some organizations like CloudResearch have developed comprehensive solutions for vetting online participants before they enter a survey.
With our SENTRY system technology, we combine simple technical checks with advanced technology like an event streamer that monitors respondents’ behavior and flags unnatural mouse movements or translation of webpage text into foreign languages. We also have respondents complete a few questions from a library of thousands of validated items to spot problems like yea-saying and inattention. Together, these processes spot and block problematic respondents before they enter your survey.
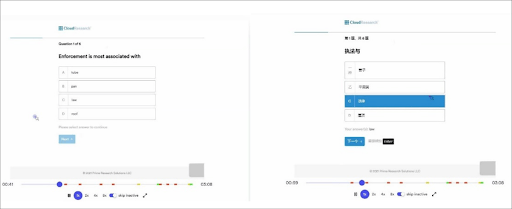
An example of the SENTRY event streamer catching a participant translating survey questions from English into Chinese. This respondent would be blocked from entering the survey.
As with any other type of fraud or complicated problem, the best defense of online data quality is multifaceted. By combining multiple different types of defenses, researchers can gain the most insight into who survey respondents are, where they are located, and how they act within the survey.
Related Articles

No, Americans Are Not Gargling Bleach: How Bad Survey Data Inflated Estimates in the Latest CDC Report – And How to Prevent This From Happening in the Future
A recent CDC report made the alarming claim that 39% of Americans engaged in high-risk behavior to avoid COVID. A new study from CloudResearch questions these claims....
Read More
Clean Data: the Key to Accurate Conclusions
Learn why survey data cleaning - separating high-quality from low-quality responses - is important in order for researchers to draw accurate conclusions from data....
Read More