Blog
What Are Survey Validity and Reliability?

Let’s start by agreeing that it isn’t always easy to measure people’s attitudes, thoughts, and feelings. People are complex. They may not always want to divulge what they really think or they may not be able to accurately report what they think. So, how do you know if your survey or test measures what you think it measures? And if it does, will it give you consistent results every time? These questions are at the heart of survey validity and reliability.
Let’s start by agreeing that it isn’t always easy to measure people’s attitudes, thoughts, and feelings. People are complex. They may not always want to divulge what they really think or they may not be able to accurately report what they think. So, how do you know if your survey or test measures what you think it measures? And if it does, will it give you consistent results every time? These questions are at the heart of survey validity and reliability.
Digging into survey validity and reliability can get a bit wonky. But, understanding these concepts is important for both the people who conduct and consume research. Thus, we lay out the details of both constructs in this blog.
What is Survey Validity?
Validity refers to how reasonable, accurate, and justifiable a claim, conclusion, or decision is. Within the context of survey research, validity is the answer to the question: does this research show what it claims to show? There are four types of validity within survey research.
While validity refers broadly to whether research shows what it claims to show, each type of validity addresses this question from a different angle.
Four Types of Survey Validity
- Statistical validity: Do the Numbers Support the Claims?
Statistical validity is an assessment of how well the numbers in a study support the claims being made. Suppose a survey says 25% of people believe the Earth is flat. An assessment of statistical validity asks whether that 25% is based on a sample of 12 or 12,000.
There is no one way to evaluate claims of statistical validity. For a survey or poll, judgments of statistical validity may entail looking at the margin of error. For studies that examine the association between multiple variables or conduct an experiment, judgments of statistical validity may entail examining the study’s effect size or statistical significance. Regardless of the particulars of the study, statistical validity is concerned with whether what the research claims is supported by the data.
- Construct validity: Are You Measuring the Right Thing?
Construct validity is an assessment of how well a research team has measured or manipulated the variable(s) in their study. Assessments of construct validity can range from a subjective judgment about whether questions look like they measure what they’re supposed to measure to a mathematical assessment of how well different questions or measures are related to each other.
Face validity – Do the items used in a study look like they’re supposed to? In other words, does your test measure appear valid on the surface? That’s the type of judgment researchers make when assessing face validity. There’s no fancy math, just a judgment about whether things look right on the surface. Face validity – Do the items used in a study look like they measure what they’re supposed to? In other words, does your test measure appear valid on the surface? That’s the type of judgment researchers make when assessing face validity. There’s no fancy math, just a judgment about whether things look right on the surface.
Face validity is sometimes assessed by experts. In the case of a survey instrument to measure beliefs about whether the earth is flat, a researcher may want to show the initial version of the instrument to an expert on the flat earth theory to get their feedback as to whether the items look right.
Content validity – Content validity is a judgment about whether your survey instrument captures all the relevant components of what you’re trying to measure.
For example, suppose we wrote 10 items to measure flat-Earth beliefs. An assessment of content validity would judge how well these questions cover different conceptual components of the flat-Earth conspiracy.
Obviously, the scale would need to include items measuring people’s beliefs about the shape of the Earth (e.g., do you believe the Earth is flat?). But given how much flat-Earth beliefs contradict basic science and information from official channels like NASA, we might also include questions that measure trust in science (e.g., The scientific method usually leads to accurate conclusions) and government institutions (e.g., Most of what NASA says about the shape of the Earth is false).
Content validity is one of the most important aspects of validity, and it largely depends on one’s theory about the construct. For example, if one’s theory of intelligence includes creativity as a component (creativity is part of the ‘content’ of intelligence) a test cannot be valid if it does not measure creativity. Many theoretical disagreements about measurement center around content validity.
Criterion validity – Unlike face validity and content validity, criterion validity is a more objective measure of whether an item or scale measures what it is supposed to measure.
To establish criterion validity researchers may look to see if their instrument predicts a concrete, real world-behavior. In our flat-Earth example, we might assess whether people who score high in flat-Earth beliefs spend more time watching flat-Earth videos on YouTube or attend flat-Earth events. If people who score high on the measure also tend to engage in behaviors associated with flat-Earth beliefs, we have evidence of criterion validity.
- External validity: Do Results Apply Beyond Your Sample?
Almost all research relies on sampling. Because researchers do not have the time and resources to talk to everyone they are interested in studying, they often rely on a sample of people to make inferences about a larger population.
External validity is concerned with assessing how well the findings from a single study apply to people, settings, and circumstances not included in the study. In other words, external validity is concerned with how well the results from a study generalize to other people, places, and situations.
Perhaps the easiest way to think about external validity is with polling. Opinion polls ask a sample of people what they think about a policy, topic, or political candidate at a particular moment. An assessment of external validity considers how the sample was gathered and whether it is likely that people in the sample represent people in the population who did not participate in the research. With some types of research such as polling, external validity is always a concern.
- Internal validity: Can You Trust the Cause-and-Effect? (for experiments)
Finally, a fourth type of validity that only applies to experiments or A/B tests is internal validity. Internal validity assesses whether the research team has designed and carried out their work in a way that allows you to have confidence that the results of their study are due only to the manipulated (i.e. independent) variables.
What is Survey Reliability?
Everyone knows what it means for something to be reliable. Reliable things are dependable and consistent. Survey reliability means the same thing. When assessing reliability, researchers want to know whether their test measures produce consistent and dependable results each time they are used.
Imagine you’re interested in measuring whether people believe in the flat-Earth conspiracy theory. According to some polling, as many as 1 in 6 U.S. adults are unsure if the Earth is round.
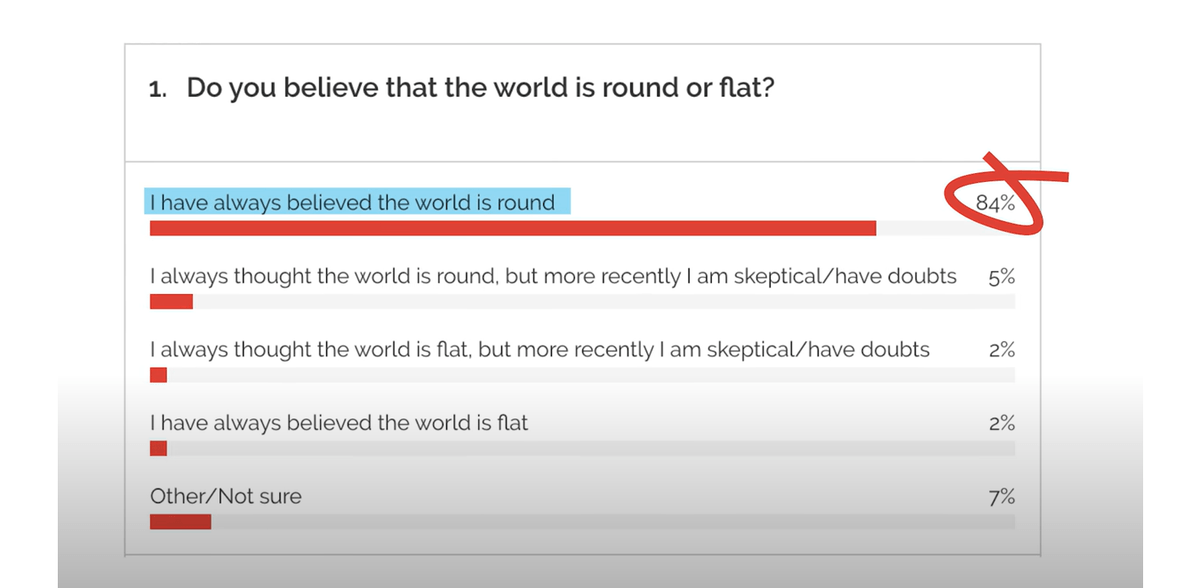
If beliefs about the roundness of the Earth are the construct we’re interested in measuring, we have to decide how to operationalize, or measure, that construct. Often, researchers operationalize a construct with a survey instrument—questions intended to measure a belief or attitude. At other times, a construct can be operationalized by observing behavior or people’s verbal or written descriptions of a topic.
Whichever way a construct is operationalized, researchers need to know whether their measures are reliable, and reliability is often assessed in three different ways.
3 Ways to Assess Survey Reliability
- Test-retest reliability
If I asked 1,000 people today if they believe the Earth is round and asked the same questions next week or next month, would the results be similar? If so, then we would say the questions have high test-retest reliability. Questions that produce different results each time participants answer them have poor reliability and are not useful for research.
- Internal reliability
Internal reliability applies to measures with multiple self-report items. So, if we created a 10-item instrument to measure belief in a flat-Earth, an assessment of internal reliability would examine whether people who tend to agree with one item (e.g., the Earth is flat) also agree with other items in the scale (e.g., images from space showing the Earth as round are fake).
- Interrater reliability
Sometimes, researchers collect data that requires judgment about participants’ responses. Imagine, for example, observing people’s behavior within an internet chat room devoted to the flat-Earth conspiracy. One way to measure belief in a flat-Earth would be to make judgments about how much each person’s postings indicate their belief that the Earth is flat.
Interrater reliability is an assessment of how well the judgments of two or more different raters agree with one another. So, if one coder believes that a participant’s written response indicates a strong belief in a flat-Earth, how likely is another person to independently agree.
Measuring Survey Reliability and Validity: Putting Things Together
The information above is technical. So, how do people evaluate reliability and validity in the real world? Do they work through a checklist of the concepts above? Not really. Remember that validity refers to the accuracy and justifiability of research claims—and evaluating it requires looking at multiple dimensions of a study.
When evaluating research, judgments of reliability and validity are often based on a mixture of information provided by the research team and critical evaluation by the consumer. Take, for example, the polling question about flat-Earth beliefs at the beginning.
The data suggesting that as many as 1 in 6 U.S. adults are unsure about the shape of the Earth was released by a prominent polling organization. In their press release, the organization claimed that just 84% of U.S. adults believe that the earth is round. But is that true?
To evaluate the validity of this claim we might inspect the questions that were asked (face validity), what the margin of error is and how many people participated in the poll (statistical validity), and where the participants came from and how they were sampled (external validity).
In assessing these characteristics, we might ask whether we would get the same result with differently worded questions, whether there were enough people in the poll to feel confident about the margin of error, and whether another sample of adults would produce the same or different results.
Some forms of reliability and validity are harder to pin down than others. But without considering reliability and validity it is hard to evaluate whether any form of research really shows what it claims to show.
Related Articles

How to Conduct an Online Brand Awareness Survey
Measuring brand awareness is vital in today's competitive digital landscape. Learn more about how to conduct online brand awareness surveys here...
Read More
How to Conduct an Online Pricing Survey
How much is your audience willing to pay for your product or service? Brands often struggle to answer this crucial question; online pricing surveys offer a fast, efficient solution....
Read More