Blog
Too Important to Get it Wrong: The Consequences and Embarrassment of Bad Data Quality

If you’re a researcher you’ve been there. You and your team have worked hard on a project for weeks—designing the study, gathering the data, analyzing the responses, and polishing your insights. Then, the moment comes when you need to hand your work to other stakeholders or share it with the world. You take a deep breath and click submit.
Most of the time, things work out fine. After all, you’ve worked hard to dot your i’s and cross your t’s. But, as a professional, you always dread WHAT IF? What if things don’t work out fine? What if there is a massive flaw with your work?
Unfortunately, people’s work sometimes has flaws and it sometimes contains critical mistakes—we are all human after all. But considering the time and money research requires, a mistake you should never make is gathering bad data because you or your sample supplier failed to vet respondents properly. Data quality is a known issue within online panels, and the stakes of not properly vetting respondents are just too high.
Consequences of Bad Data at the CDC
You probably don’t need to be reminded, but things were scary early in the COVID-19 pandemic. The virus was new, scientific evidence was scant, public policy was inconsistent, and there were no effective treatments or vaccines. Amid rising infections and deaths, people didn’t know how to keep themselves safe besides avoiding others.
Worried about what actions people may take to ward off COVID-19, the CDC released a report in June 2020 titled “Knowledge and Practices Regarding Safe Household Cleaning and Disinfection for COVID-19 Prevention.” The results were alarming. According to the study, “39% of Americans engaged in at least one high-risk behavior during the previous month.” These behaviors included using bleach to wash food items (19%), using household cleaning products on the skin (18%), and drinking or gargling diluted bleach, soap, or other disinfectants (4%).

As you might expect, these findings garnered a lot of media attention. Within days, hundreds of news outlets worldwide reported that Americans were doing things like drinking and gargling bleach to avoid COVID-19. Although the news traveled fast, the findings were false.
When the CDC gathered their data, they contracted with a market research vendor. The vendor sourced respondents from a common sample supplier but failed to vet respondents to ensure they answered honestly and that problematic respondents did not muck up the data. We know this because CloudResearch replicated the CDC study. We obtained the same results using the same questions and sample suppliers when we gathered the data without vetting respondents. When we vetted respondents with our patented Sentry® system, however, the data told a different story.
Respondents vetted with Sentry reported far fewer dangerous cleaning practices than those who were not vetted. In most cases, the gap between vetted and non-vetted respondents was close to 20%. Further, for the most high-risk behaviors of drinking or gargling dangerous cleaning solutions, the percentage of people saying “yes” almost disappeared among vetted respondents.
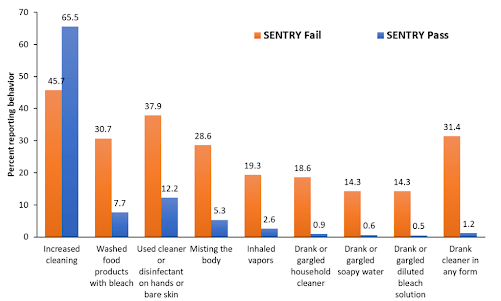
On its face, the idea that almost 40% of Americans are dangerously using cleaning products is a bit hard to believe. The data CloudResearch gathered show why: the numbers were inflated by inattentive respondents. Inattentive respondents answer randomly and say “yes” to statements like “I eat concrete for breakfast due to its iron content.” Not coincidentally, these are the same respondents who reported gargling bleach in our studies.
There are multiple, negative societal consequences of the CDC’s messy data. At a minimum, such false reports risk damaging the CDC’s reputation and introducing professional embarrassment among the researchers who gathered the data but failed to vet it properly. More importantly, the CDC recommended costly public health interventions to combat a problem that did not exist. The societal implications of this false CDC report were discussed in a recent article in Harvard Business Review.
How to Avoid the Embarrassment of Bad Data
As unpleasant as it is to think about the professional embarrassment that can come from suspect data, the good news is there are steps you can take to prevent these sorts of mistakes. Three steps you can take are to: add data quality measures to your survey, ask your sample provider for evidence of what they’re doing to deal with these issues, and consider a tool like Sentry.
- Add Data Quality Measures to Your Survey
If you are not already adding data quality measures to your surveys, there is no time like the present to start. But the truth is, for most researchers, it is standard practice to include measures of attention and quality within surveys. Therefore you may not need to consider whether you should add data quality measures but if you’re adding the correct ones for data quality checks.
At CloudResearch, we’ve written about good and bad data quality checks. Our recommendation is to include a few, short and simple measures of attention and at least one open-ended item. Combining these data points with other measures of response tendencies is a good starting point for evaluating response quality.
- Talk to Your Sample Provider and Ask for Evidence
Every sample provider will say they do something to improve data quality. But the questions you need to ask have to do with what specifically your sample provider is doing and whether they have evidence (data!) of how effective it is.
If there is one thing that is clear from the CDC study, the industry standards are currently insufficient for ensuring quality data.
Some questions you might ask your partners or sample provider include:
Who is providing the sample?
Who is vetting the quality of the sample?
Are some of the respondents bots or fraudulent actors?
What are best practices for eliminating inattentive respondents?
What kinds of vetting are you doing before people reach my survey?
What data do you have on the effectiveness of your screening methods? - Consider a Tool Like Sentry
While both options above are good steps to take, the best way to improve data quality is to prevent bad respondents from ever entering your survey. That is what Sentry does.
As a pre-study vetting system, Sentry screens respondents with both technical and behavioral measures. Respondents who show evidence of inattention, yea-saying, technical fraud, or other questionable behaviors are routed away from the survey, while those who show evidence of attention and engagement proceed to the study. Sentry takes 30 seconds for respondents to complete but has a big impact on data quality. And, you can use Sentry to vet respondents from any online source!
The research you do is too important to get wrong. When respondents provide data that is incorrect, unreliable, or inaccurate and these issues go undetected it can create a precedent that you and your organization are not a credible source. Taking these three simple steps can help you avoid the consequences of bad data quality.
Sentry can be an essential aid in vetting respondents.
Related Articles

Comparing Data Quality on CloudResearch to Prolific: a Reply to Prolific's Recent False Claims
Reply to MTurk, Prolific or panels? Choosing the right audience for online research...
Read More
How Non-Response Bias Can Affect Research Surveys
Nonresponse bias can impact even well-run research. Learn how you can avoid this fundamental risk to data quality in your online surveys....
Read More