Blog
Comparing Data Quality on CloudResearch to Prolific: a Reply to Prolific's Recent False Claims

By Leib Litman, PhD, Aaron Moss, PhD, Cheskie Rosenzweig, MS & Jonathan Robinson, PhD
It’s All About Data Quality
When it comes to online research, few topics loom as large as data quality. With recent well-documented cases of problematic respondents and fraud (Moss & Litman, 2018), data quality is often one of the key considerations when researchers choose a platform for online data collection.
A Few Words About Us
CloudResearch has been a leader in developing data quality tools across the online sample ecosystem. Over the last several years we have conducted numerous research projects to understand the sources of problematic data and developed tools to mitigate those problems. Our data protection tools are used on Mechanical Turk and hundreds of other participant recruitment platforms. Our CloudResearch-Approved group of participants on MTurk is used for hundreds of studies each day, and our Sentry tool is used by numerous panel platforms. We regularly offer webinars to provide helpful information about online data quality. In just the last two weeks, our webinars have been attended by over 300 researchers from numerous institutions in the United States and around the world.
The tools we created have a track record of providing the most advanced and effective scientifically-driven solutions to data quality problems in online data collection. This is not just what we say about ourselves. This is what others say about us!
Prolific’s False Claims
Two weeks ago, a researcher and four people affiliated with Prolific, including their founder, published a preprint on SSRN in which they compared data quality on Prolific, Mechanical Turk, CloudResearch, and two online panels. The paper reported that data quality on Prolific is vastly superior to other platforms including CloudResearch. Moreover, the authors went so far as to say that using other platforms “appears to reflect a market failure and an inefficient allocation or even misuse of scarce research budgets” (pg., 21).
The problem is that when collecting data on CloudResearch, their team shut off CloudResearch’s data quality tools prior to running the study. Here is a screenshot of their study’s settings from the CloudResearch Dashboard. Not only did these researchers shut off CloudResearch’s tools, but they also shut off what are widely considered standard tools on Mechanical Turk (reputation qualifications). These surprising methodological practices were not disclosed anywhere in their manuscript, potentially obscuring this information from the scrutiny of peer-review. Many of these tools are on by default within CloudResearch, so we know that these tools were removed intentionally.
Dashboard view of Prolific’s study on CloudResearch with data quality filters turned off:
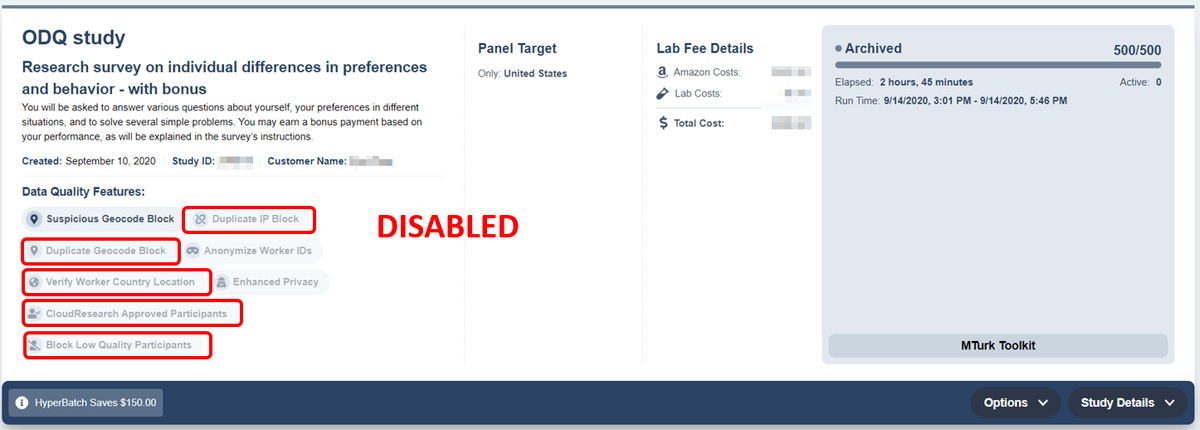
Turning off data quality filters and then considering low-quality data as an indictment of a platform is akin to knocking down the walls of a house and then being upset about getting cold and wet.
Because the Prolific study is on SSRN, it will have the weight of a scientific publication even if it is never published in a peer-reviewed journal. And unfortunately, preprints and published manuscripts with incorrect information can still be influential and heavily cited. For this reason, we felt compelled to directly respond to the claims in their paper with our own SSRN preprint.
To interrogate their claims, we replicated their study on CloudResearch using the exact same stimuli. The only difference between their study and ours was that we used our CloudResearch-Approved group of participants, which is the recommended setting when collecting data with the CloudResearch MTurk Toolkit.
We found that the CloudResearch data was notably better than what Prolific reported in their paper and even better than the data they gathered from the Prolific platform. We wrote up our results in a response letter which is on SSRN. For readers who may be interested, we outline what we see to be major issues with their paper below.
We Will Fund a Replication Study
We understand the implications of CloudResearch having collected our own data to refute someone else’s claims about data quality on our platform. We are completely confident that our results will replicate across all measures reported (plus/minus a few percentage points). In order to dispel any doubts about the validity of our report we are making the following offer: We would be happy to fund a research study, paying all participant fees on both CloudResearch and Prolific, for researchers who may want to replicate the effects we describe in our SSRN report. The stimuli for this replication study can be found on our or Prolific OSF links. Funding would include 500 respondents on CloudResearch and Prolific (N = 1000 total), the number that was collected in both CloudResearch and Prolific studies. If there is interest from multiple research groups we can help facilitate communication between collaborators. We would not be involved in the data analysis or data collection but would just make sure that that the CloudResearch platform is used as intended—with the data quality filters that we worked so hard to build, turned on. Prolific should have the opportunity to do the same on their end.
A Deeper Dive Into Problems With Methodology and Interpretation
Our SSRN preprint outlines many of the problems with how Prolific conducted their study. We think unpacking some of these issues will be of interest to many people who conduct online research and for any would-be reviewer of their paper.
Platforms cannot be evaluated in the absence of the data quality tools they work hard to make available.
As we have outlined above and on our SSRN preprint, CloudResearch data quality tools were turned off in the Prolific study. This by itself is enough to invalidate their findings and for their preprint to be retracted in full. In the absence of CloudResearch’s data quality filters, there is no basis to say that the data was collected from CloudResearch. Sampling from CloudResearch without the default data quality tools is the same as sampling from Mechanical Turk directly. Thus, rather than comparing the data quality of MTurk and CloudResearch, Prolific effectively sampled MTurk twice—something that explains why their numbers for CloudResearch and MTurk were virtually identical.
Studies that do not report methodological details prevent readers and reviewers from scrutinizing the results and interpretations.
Prolific failed to report many methodological details that would enable readers and reviewers to fully evaluate their work. As we’ve already made clear, the paper does not report that CloudResearch’s data quality tools were turned off or that MTurk’s reputation qualifications were not used. The paper also lacks details on what, if any, sampling criteria were specified when sampling directly from MTurk or from Prolific. For example, MTurk’s reputation qualifications were not used. But that is never mentioned in the methods section, nor do the authors explain why they chose not to use those qualifications. We do not suspect that the authors used features like reputation qualifications on some platforms and not others, but readers need these details in order to evaluate the study’s findings.
No platform meets the needs of all research studies.
Prolific concludes that using platforms other than Prolific “appears to reflect a market failure and an inefficient allocation or even misuse of scarce research budgets.” But, even if Prolific data were superior to all other platforms (which it isn’t), to suggest that the use of other platforms is a misuse of funds reflects a profound misunderstanding of the online research landscape.
As just one example, The New York Times contracted with Dynata—one of the panels considered in Prolific’s paper—in July 2020 to gather 250,000 survey responses from people all over the U.S. in just a two-week period. That’s more people collected in two weeks than can be collected from Prolific or MTurk in two years. Surely, this study is a valuable contribution to the understanding of human behavior and not a misuse of research funds.
As we write in our SSRN preprint and our recent book, we advocate for a “fit for purpose” approach when choosing a platform. This approach emphasizes selecting a participant platform based on the match between a study’s goals and the platform’s strengths and weaknesses. All platforms have strengths and weaknesses. This means certain studies will be better suited for some platforms over others, despite the limitations any one platform may have.
Mechanical Turk CAN be used to collect great data. You just need to use the right tools.
Importantly, Prolific’s conclusions about data quality are not only wrong about CloudResearch; they also reflect a misunderstanding about what Mechanical Turk is, and it was intended to be.
MTurk was designed so that workers and requesters can develop tools and extensions that meet their needs. The CloudResearch Toolkit, with its Approved group of workers, is one such extension. The CloudResearch Toolkit was built to meet the needs of social science researchers (Litman et al., 2017), including addressing issues of data quality. Because the CloudResearch Toolkit is an extension of Mechanical Turk it is impossible to claim that high-quality data can be collected on CloudResearch but not on Mechanical Turk. In other words, as we stress above, a research platform cannot be evaluated in the absence of the tools that are available to use on that platform.
No platform is immune from online fraud.
Banks, cities, Fortune 500 corporations, and a large portion of the U.S. government all deal with the consequences of bad actors online and sometimes get hacked. No online platform is immune from fraud.
The data quality of a platform can change over time and platforms may need to develop and implement novel tools to address emerging threats to data quality.
Data quality is not a time invariant platform characteristic. To insinuate, as done by Peer et al, that any particular platform is protected from online fraud based on one specific demonstration of satisfactory data quality is erroneous. That applies to any platform, including CloudResearch.
Just because you are not sampling specific demographics does not mean the sample is random.
The Prolific paper is misleading about the mechanisms that may produce some sample differences from each platform. For example, the authors state, “We did not select any demographic quotas, so these demographic breakdowns represent a random sample of the platform or panel” (pg. 6). This is entirely incorrect. The only way to gather a random sample from each platform is to use a probability-based sampling approach.
This misleading statement matters because later discussion encourages readers to view characteristics of the samples gathered as evidence of platform differences. In reality, some of these differences are due to default characteristics of how these platforms operate–defaults that in some cases can be changed. The result is that sample-level characteristics are often very different from platform-level characteristics, as we discuss more in the next section.
For example, on Mechanical Turk studies are posted to the worker dashboard. Unless the researcher specifies qualifications that limit who can take the study, people participate on a first-come, first-served basis (Litman, Robinson, & Rosenzweig, 2020, Ch. 7). This results in highly active workers being more likely to take the study first. And, thus, samples typically reflect the demographics of more active participants.
While we do not have complete knowledge of how sampling operates on Prolific, public information leads us to believe that notifications are sent to participants. Typically, systems that send these notifications are set up to prioritize less active and less experienced participants, which is a nice feature from a research perspective. But the failure to acknowledge these platform differences in sampling and then to present sample characteristics as evidence of platform differences in participant experience, usage, etc. is highly misleading.
Most people on MTurk are not men. And other misconceptions arising from sample point-estimates.
The Prolific paper reports that only a third of people in their MTurk and CloudResearch samples are women. And, as we have pointed out above, the paper encourages readers to view these point estimates as representations of the platform. In fact, however, most people on MTurk are not men. They are women.
Historically, the percentage of participants who identify as female has been near 57% (Robinson, Litman, & Rosenzweig, 2020; Ch. 6). Yet because men are often more active than women, the percentage of HITs completed by each group is near 50%. The figure below shows the percentage of HITs completed by women on CloudResearch over five years and also the percentage of women in the CloudResearch-Approved group. All numbers are near the 50% mark.
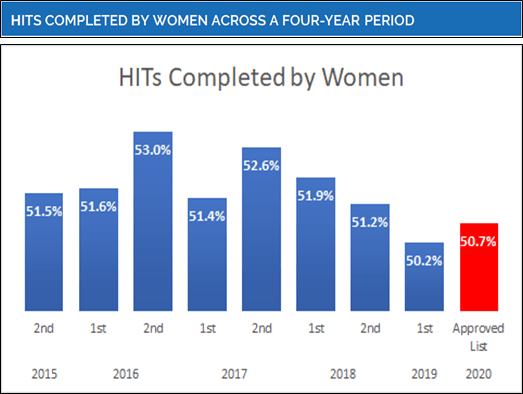
Although the percentage of men and women at the platform level is a near even split, we know that the demographics within any one sample show wide variability. Depending on factors such as pay, study length, and how a study is advertised, the percentage of men can range from as low as 25% to as high as 75% (Robinson, Litman, & Rosenzweig, 2020; Ch. 6). Thus, to present a single sample point estimate as evidence of platform characteristics is inaccurate and misleading.
Mechanical Turk does not have a naïvete problem. It’s all about how researchers sample.
To pick up on the point from above, the Prolific study reports several details about whether participants use multiple platforms, the number of hours they spend on these platforms per week, and what can generally be viewed as details about participant naivete. Although many researchers have the perception that people on MTurk are not naive—a perception reinforced by the Prolific paper—this perception is mistaken.
The majority of people on MTurk are not superworkers, but occasional users. When examining the MTurk platform a few years ago, we reported that about 55% of the entire platform was relatively inexperienced (Robinson et al., 2019). We also demonstrated how researchers can sample new people who tend to be inexperienced with research studies very easily on Mechanical Turk. In other words, sample characteristics are often determined by how researchers sample from online participant platforms.
Qualtrics and Dynata do not sample from the same larger pool.
Qualtrics and Dynata are completely different online ecosystems. Dynata has its own panel. Its participants come from that panel, unless there is a need to sample from other sources. Dynata’s panel is one of the largest and most widely used in the world and there would be no need to go beyond their sample to recruit 500 people.
Qualtrics, on the other hand, does not have its own panel. Instead Qualtrics gets sample from other suppliers. While it is possible for Qualtrics to collect data from Dynata, it is highly unlikely in this case. For Prolific’s study, Qualtrics likely got their sample from Lucid or similar suppliers.
Prolific’s paper tentatively suggested that Qualtrics and Dyanata may sample from the same larger pool because their participant IDs (the alphanumeric strings supplied by panels to uniquely identify participants) looked similar. To quote, they said, “We weakly suspect that both platforms actually sample from the same larger population, because we observed that the distinct format of the users’ IDs in both samples we received was very similar (but we have no way to corroborate that).”
There is no basis for this suggestion and it is misleading to researchers. The participant IDs are similar across the industry and provide no indication as to which platform participants are sampled from.
There is (virtually) no such thing as a large sample with zero dropout.
Prolific reports dropout across participant recruitment platforms. When reporting dropout for CloudResearch, the authors state, “Because CR recruit subjects from MTurk using "micro-batches" (batches of 9 submissions per HIT) it avoided drop-outs completely” (pg. 6). This, too, is incorrect.
Microbatch and hyperbatch are options that break a study into multiple HITs, but they do nothing to limit dropout. It’s hard to imagine what could prevent a participant who doesn’t want to continue from closing their browser. In addition, a bedrock principle of research ethics is that participants must be allowed to discontinue participation in a study if they wish. We do not have a way to limit dropout.
Were participants on Prolific paid more than on MTurk and CloudResearch?
It appears participants were paid more on Prolific than on MTurk or CloudResearch. “Participants were paid 1.5 GBP (British Pound) on Prolific, 1.5 USD on MTurk and CR…”. On September 14, the date the study was run, that would have amounted to $1.92 payments to Prolific participants. Paying people in British Pounds may have made sense if they resided in Europe. But participants were recruited from the United States on all platforms.
It is unclear why Prolific participants were paid more. But the literature is clear that incentives can influence outcomes (e.g. dropout rate, performance on creative tasks etc). We believe most reviewers would reject the paper based on this issue alone. (We hope that payments in GBP is a typo, but it does not appear to be based on reported Prolific study costs; see their footnote 1, p6).
Related Articles

Best Practices That Can Affect Data Quality on MTurk
Amazon's MTurk has given researchers a powerful tool for connecting to survey respondents online. See how six simple best practices can help improve your data quality....
Read More
Clean Data: the Key to Accurate Conclusions
Learn why survey data cleaning - separating high-quality from low-quality responses - is important in order for researchers to draw accurate conclusions from data....
Read More