Blog
How Can You Get High-Quality Data from Amazon's Mechanical Turk? With CloudResearch's Approved Participants!

Highlights:
The reputation system on Mechanical Turk does not work
CloudResearch’s Approved Participants delivers high-quality data from MTurk via our MTurk Toolkit
A new study demonstrates the effectiveness of CloudResearch’s Approved Participants
If you need someone to perform a job—replace your roof, aerate your lawn, haul away your garbage—you might choose who to hire by using information about the person’s reputation. A person with a good reputation can usually be counted on to uphold their end of the bargain, to follow through on commitments, and to get the job done right. A person with a bad reputation, on the other hand, can probably be counted on to give you headaches.
Humans have used information about other people’s reputations for tens of thousands if not hundreds of thousands of years. Given people’s fluency with tracking others’ reputations it is not surprising that many tech platforms rely on reputation systems to help regulate transactions between strangers (think Airbnb reviews). For behavioral researchers who use Amazon Mechanical Turk (MTurk), the story is no different: many researchers rely on reputation metrics when sampling participants.
Why the MTurk Reputation System is Broken
From MTurk’s inception until today, behavioral scientists have tried to manage data quality using reputation qualifications. Often, researchers will require participants to have a 95% approval rating and at least 100 prior HITs completed, if not more. Even though research has questioned the effectiveness of these qualifications and shown that using them leads to a more experienced sample of participants, many researchers continue to apply such qualifications. We believe it’s time for this practice to stop.
The reason is simple: MTurk’s reputation system is broken. For a reputation system to be effective people have to do the work of correcting those who engage in bad behavior. For several years now, bad behavior on MTurk has remained unaddressed.
According to CloudResearch data, across more than 40 million surveys submitted through our MTurk Toolkit just 0.5% have been rejected by researchers (Litman & Robinson, 2020). And, this low rate of rejection is despite a marked increase in fraud, misrepresentation, and low-quality data beginning in 2018.
The Most Effective Alternative to MTurk’s Reputation System: CloudResearch’s Approved Participants
Researchers may fail to reject low-quality responses on MTurk for several reasons, but the consequence is always the same: inflated reputation metrics for participants on MTurk.
Inflated reputation qualifications mean that MTurk’s reputation system cannot reliably separate people who provide high-quality data from those who provide low-quality data. It also means that another system is needed to selectively sample high-quality participants. CloudResearch’s Approved Participants is that alternative system—and has proven efficacy.
Since the summer of 2020, CloudResearch has been vetting participants on MTurk. To date, about 200,000 MTurk participants have completed our vetting process. People who pass our vetting measures are added to CloudResearch’s Approved Participants, those who fail are placed onto a Blocked Group, and the small number who never participate in our measures remain part of the MTurk ecosystem but do not have access to studies run through CloudResearch.
To place people on CloudResearch’s Approved Participants we rely on three types of information:
1) researcher-generated data.
2) a series of measures administered by CloudResearch to MTukers.
3) technological measures that are gathered by CloudResearch.
Collectively, these measures are aimed at identifying a participant’s level of attention and capability to accurately respond to survey items. People who demonstrate that they are unwilling or unable to provide quality data are blocked from CloudResearch-hosted studies. Meanwhile, people who provide high-quality responses are placed into CloudResearch’s Approved Participants and made available for sampling from the CloudResearch MTurk Toolkit.
Evidence that CloudResearch’s Approved Participants Improves Data Quality
In a recent paper published at Behavior Research Methods, the CloudResearch team collaborated with David Hauser, a professor of psychology at Queen’s University and someone with expertise on MTurk, to investigate data quality on MTurk.
We gathered data from 300 people in the CloudResearch Approved Participants group, 300 people in our blocked group, and 300 people on MTurk regardless of their vetted status. For the open MTurk sample we only required that participants have a 95% Approval Rating and at least 100 prior HITs completed.
We administered several measures of data quality to participants and examined the predictive validity of the Approved Participants and Blocked groups. We show just a few of the results here, but the full report can be accessed here.
Performance in Mock Vignettes
Participants are often asked to read short stories, or vignettes, before answering questions. Given that this is a common task in online research, we investigated how participants performed in “mock vignettes” adapted from past research. Participants read two vignettes and answered three questions about each story for a total of six possible questions.
Participants in the Blocked group answered the fewest questions correctly followed by those in the Open MTurk group and then those in the Approved Participants group. The differences between all three groups were statistically significant.
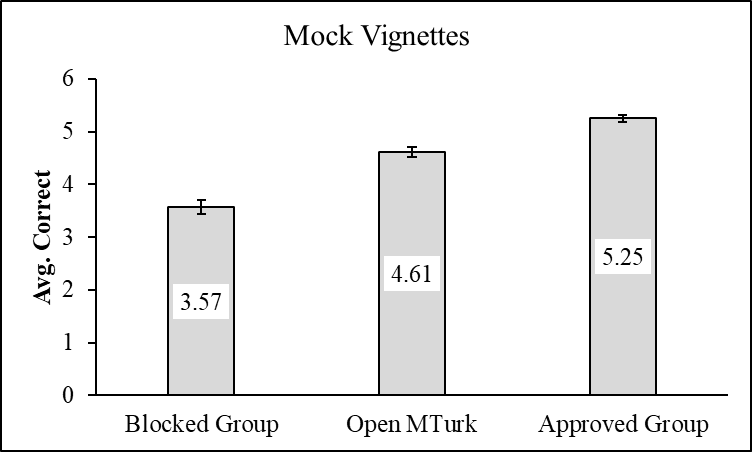
Note: Participants were asked six questions. Numbers shown in each bar are group means. Error bars represent standard errors.
Attention Checks
Like vignettes, attention checks are a staple within online research. We included four attention check questions with factually incorrect answers throughout our study (e.g,. “I work 28 hours in a typical workday”). Each groups’ performance on these measures is depicted below.
Generally speaking, all three groups performed well passing at least three attention checks on average. However, there were statistically significant differences between groups with participants in the Approved Participants group answering more questions correctly than either of the other two groups.
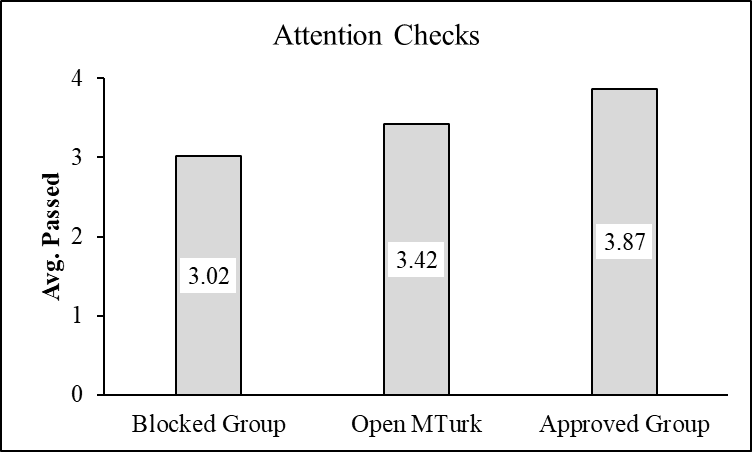
Note: Participants were asked four questions. Numbers shown in each bar are group means. Error bars represent standard errors.
Experimental Effects
The study included four well-established psychological effects like the soda framing task. In this task, participants are asked how much they would be willing to pay for a soda on a hot day. Some participants are told the soda will come from a run-down grocery store while others are told it will come from a fancy hotel resort. People typically are willing to pay more for the soda when it comes from the resort than the grocery store.
Our study replicated this effect in the Approved Participants group and the Open MTurk sample (albeit with a smaller effect size) but not in the blocked group.
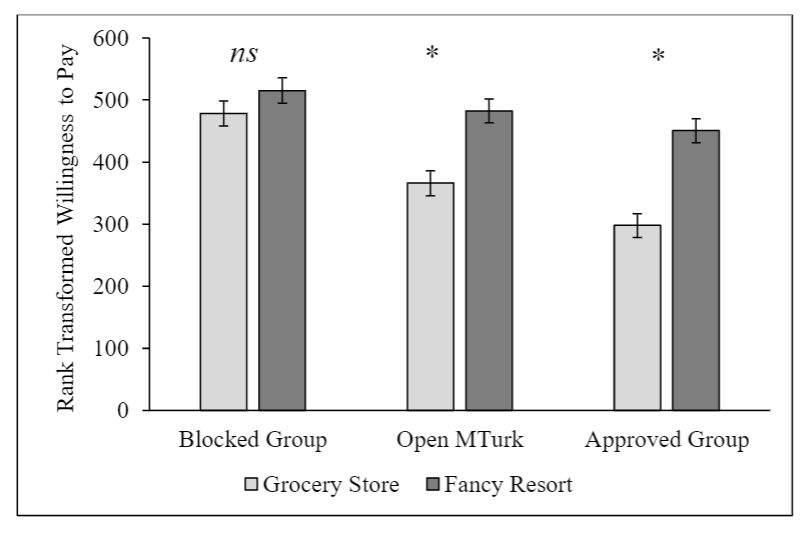
Note: Scores are rank transformed averages. Error bars represent standard errors.
Before we could analyze the data in the anchoring task or other experiments with open-ended response formats, we had to extensively clean it.
In the soda task, for example, participants reported being willing to pay between $0 and $780,000 for a soda. We identified outliers (> $20) and compared implausible responses across groups. Approved Participants group gave fewer implausible responses [3.0%] than the Open Sample [18.8%] or the Blocked group [35.8%], which is itself a marker of data quality. We observed similar patterns of messy data on other measures.
Cheating
We assessed cheating by presenting people with a set of political knowledge questions (e.g., how many years does a US Senate term last?) and asking them not to Google the answers. After people answered the questions, we asked them to report whether they used Google. We also used embedded data within the survey to tell if participants ever left the survey window during the political knowledge questions–a behavior that would suggest cheating.
More than 26% percent of participants in the blocked group self-reported cheating when explicitly asked not to cheat. In the open MTurk sample this number was near 15% and in the Approved Participants group the number was 3.3%. The surreptitiously recorded survey data confirmed these patterns of cheating.
How to Think About CloudResearch’s Approved Participants
CloudResearch’s Approved Participants is a vetted pool of over 100,000 participants on MTurk who provide high-quality data across a variety of measures and surveys.
Participants within the Approved Participants group match the overall demographics of MTurk and are not overly experienced–the average participant has completed less than 15 surveys. New participants are added to CloudResearch’s Approved Participants each month, and CloudResearch has the ability to selectively sample or notify participants about studies on behalf of researchers.
We like to think CloudResearch’s Approved Participants returns MTurk to where it was before fraud and other data quality problems began to plague the site in 2018, and our data indicate that using our Approved Participants yields significantly better data quality which will save researchers’ the time and effort required to sort through noisy datasets gathered from MTurk directly.
Interested in collecting high-quality data with our Approved Participants? Sign up or request a demo of our MTurk Toolkit today!
Related Articles

Best Practices That Can Affect Data Quality on MTurk
Amazon's MTurk has given researchers a powerful tool for connecting to survey respondents online. See how six simple best practices can help improve your data quality....
Read More
9 Strategies to Enhance Quality of Data in Online Research
Collecting quality data begins with selecting the right participants. A phrase common in many research circles is that participant selection should be “fit for purpose.” This means the participants a...
Read More