Research
Tapped Out or Barely Tapped: Debunking Common Issues With MTurk's Participant Pool

By Aaron Moss, PhD Cheskie Rosenzweig, MS, & Leib Litman, PhD
Economists and psychologists spend a lot of time studying social dilemmas — situations in which people face a choice to act in self-interest or to cooperate with others. One particular social dilemma is the tragedy of the commons. In the tragedy of the commons, people must decide whether to use a shared resource in a way that maximizes self-interest or balances self-interest with the collective interest. An example is commercial fishing.
If each fishing boat catches only what it needs to earn a profit and to feed people, schools of fish will replenish themselves. However, if each boat seeks to maximize profits by catching as many fish as possible, then fish populations will dwindle, making it harder for everyone to catch fish in the future.
Although social scientists usually study people’s behavior in social dilemmas, some researchers have suggested that social scientists are engaged in a social dilemma of their own when it comes to the use of Amazon’s Mechanical Turk (MTurk) (Chandler, Mueller, & Paolacci, 2013).
Since 2011, MTurk has been the platform of choice for academic researchers seeking to collect data online. Yet due to MTurk’s popularity and the relative ease of running studies online, there is a growing sense that MTurk is oversaturated. In a recently published paper (Robinson, Rosenzweig, Moss, & Litman, 2019), the CloudResearch team investigated this issue and brought some clarity to the question of whether MTurk is a tragedy of the commons.
Broadly, our research finds that MTurk is not oversaturated. Instead, the sampling practices used by researchers restrict the pool of available participants, making it appear as if there are far fewer people on MTurk than there are. We suggest that, with different sampling strategies, researchers can harness the vast and untapped potential of the MTurk platform.
Three Central Problems That May Suggest MTurk is Oversaturated
There are three related issues that we must consider when asking whether MTurk is overused:
Uncertainty over the exact size of MTurk’s subject pool.
Angst about the super-worker problem.
Concern that the average MTurk worker has been repeatedly exposed to common experimental measures and manipulations.
1. How Many MTurk Workers Are There?
The question of whether workers are overused relates to knowing how many people are on MTurk. Unfortunately, it is difficult to ascertain how many people are active on MTurk.
Amazon advertises more than 500,000 registered workers. Yet academic researchers have estimated that the average lab has access to less than 10,000 people in any three-month span (Stewart et al., 2015) and the total number of active people may be around 100,000 (Difallah, Filatova, & Ipeirotis, 2018).
The CloudResearch team examined how many participants are on MTurk by analyzing metadata from studies run on our platform. From the data, we saw that there were 250,810 MTurk workers worldwide who have ever completed a study posted through CloudResearch. We examined metadata from January 2016 through April 2019 to gauge U.S. worker activity. As shown in Figure 1, approximately 85,000 people completed studies each year. Furthermore, over half of the unique workers were new to the platform.
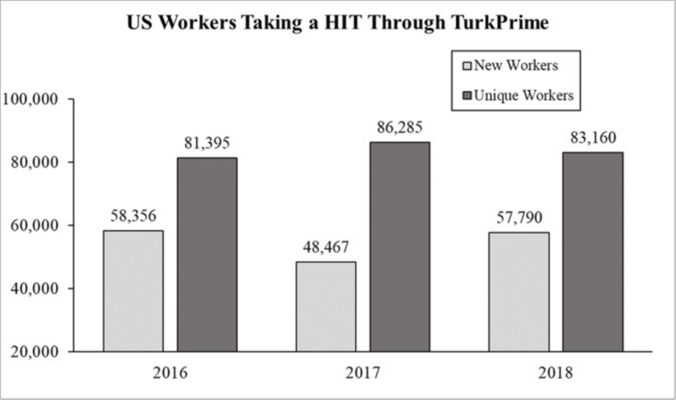
An immediate question raised by these data is: How can researchers believe MTurk is overused if there are more participants than previously thought and more than half of those participants are new to the platform each year? A partial answer comes from the super-worker problem.
2. MTurk’s Super-worker Problem
Super-workers are people on MTurk who complete tens of thousands of HITs, constituting far more than their share of the population. Super-workers contribute to concerns that MTurk is overused because they wind up in many studies on the same topic. Prior research has suggested that 20% of workers may complete as much as 80% of all HITs. The data examined by CloudResearch supports that estimation. Our data shows that roughly 27% of people complete approximately 87% of all HITs. Shockingly, 5.7% of people complete 42.2% of all HITs!
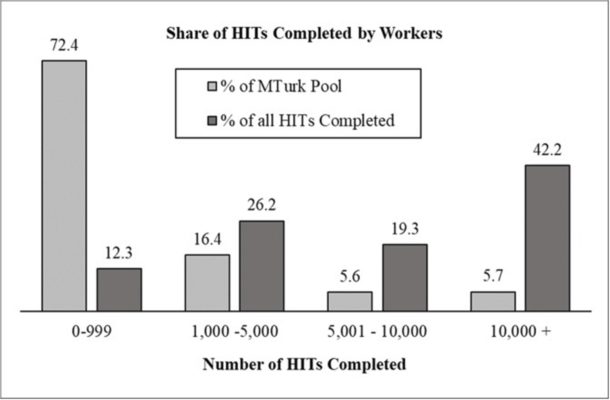
Why do super-workers end up in so many studies? There are several contributing factors:
Super-workers spend more time on MTurk than other people, which means super-workers are faster at grabbing HITs when they appear.
Super-workers are more likely than less-experienced workers to use tools that automatically grab the highest paying HITs.
The worker qualifications most researchers use — a 95% approval rating and at least 100 previous HITs completed — systematically exclude inexperienced workers, making it easier for super-workers to participate in studies.
The idea that standard worker qualifications may contribute to the super-worker problem has been entirely overlooked by researchers, in part, because the problem is difficult to see. Most researchers believe that using worker qualifications of a 95% approval rating and at least 100 HITs completed are necessary to maintain data quality. However, these qualifications block around 35% of workers who have less than 100 prior HITs and help skew a study’s sample toward experienced workers who have often completed thousands of HITs.
Our research investigated whether worker qualifications have a role in maintaining data quality by conducting some experiments.
3. “Average” MTurk Worker Familiarity With Common Measures and Manipulations
In 2 experiments, we investigated how the data from inexperienced MTurk workers (i.e., people with less than 50 HITs completed) compared to standard workers (i.e., people with >95% approval rating and at least 100 HITs completed). We compared these groups on multiple measures of data quality and assessed their previous exposure to our measures and manipulations.
Across all measures of data quality, we found little to no difference between inexperienced and experienced workers. People who had completed less than 50 previous HITs provided reliable responses, passed attention check questions and provided experimental effect sizes equal to people with thousands of previous HITs completed.
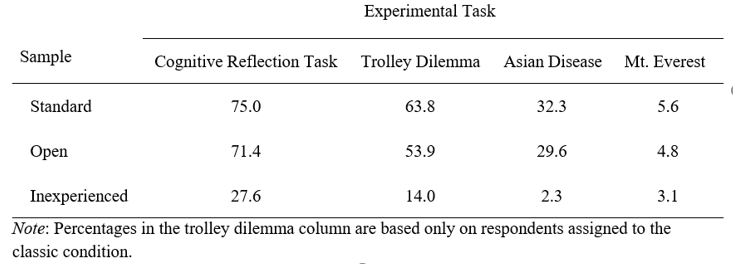
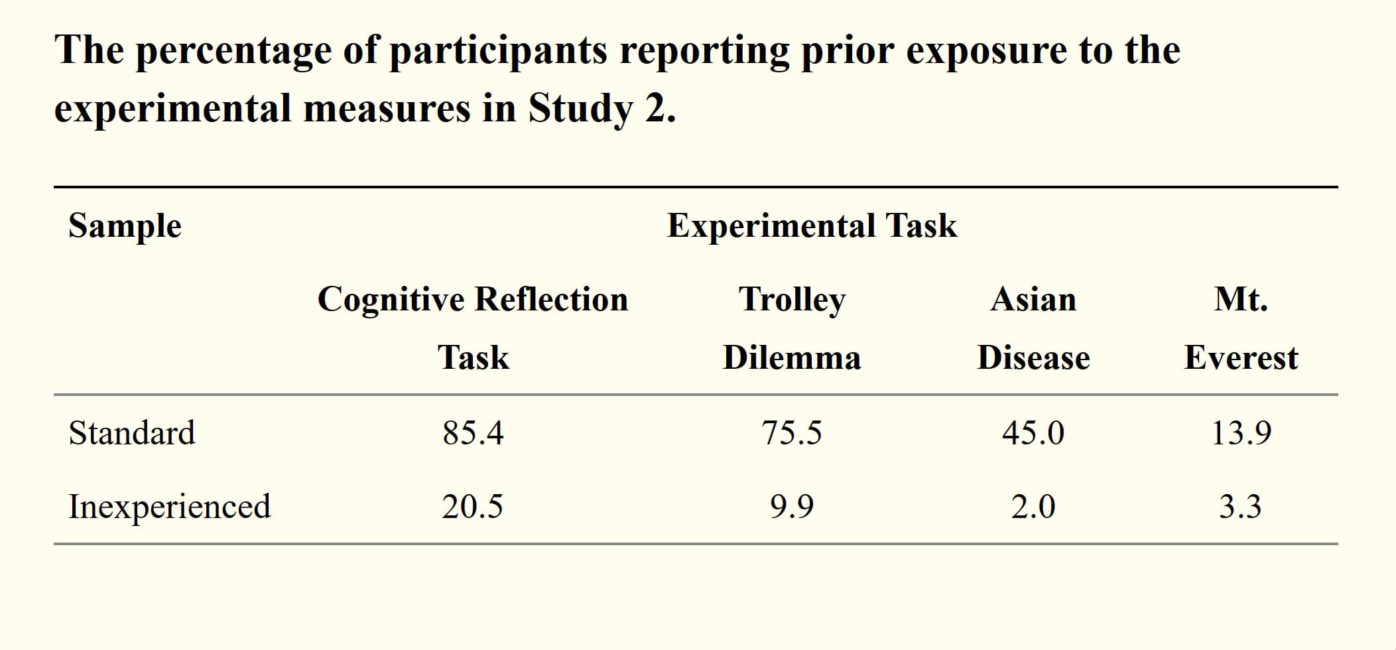
After participants completed each experimental task, we asked if they had ever seen the task previously. Their responses are in Tables 1 and 2. On three of the four tasks, inexperienced participants reported much less prior exposure than the experienced participants. Altogether, the results of our studies suggest researchers may be able to recruit naive participants on MTurk who provide quality data.
Take Advantage of MTurk With New Sampling Strategies
Despite growing concern among researchers that MTurk is overused, our research team found evidence that there is a large, naive, and untapped pool of participants that researchers can sample by changing sampling strategies. Sampling inexperienced workers, by excluding workers who have taken an extremely high number of HITs, will significantly increase the available pool of MTurk participants, mitigate the super-worker problem, and help solve the non-naive problem. These practices may allow researchers to benefit from the advantages that originally made MTurk an attractive source of research participants.
References:
Robinson, J., Rosenzweig, C., Moss, A.J., & Litman, L. (2019) Tapped out or barely tapped? Recommendations for how to harness the vast and largely unused potential of the Mechanical Turk participant pool. PLOS ONE 14(12).https://doi.org/10.1371/journal.pone.0226394
Chandler, J., Mueller, P., & Paolacci, G. (2014). Nonnaïveté among Amazon Mechanical Turk workers: Consequences and solutions for behavioral researchers. Behavior research methods, 46(1), 112-130.
Difallah, D., Filatova, E., & Ipeirotis, P. (2018, February). Demographics and dynamics of mechanical Turk workers. In Proceedings of the eleventh acm international conference on web search and data mining (pp. 135-143). ACM.
Stewart, N., Ungemach, C., Harris, A. J., Bartels, D. M., Newell, B. R., Paolacci, G., & Chandler, J. (2015). The average laboratory samples a population of 7,300 Amazon Mechanical Turk workers. Judgment and Decision making, 10(5), 479-491.
Related Articles

What Is Prime Panels? Breaking Down CloudResearch's Panel Management Tool
The way researchers find subjects has changed dramatically over the last century. Techniques and standard practices have shifted from an original emphasis on self-study and...
Read More
Does It Matter What Time of Day a Survey Is Sent Out?
If you have worked in behavioral research during the last decade, you know the Internet has changed things. Market researchers, pollsters, and academics have all turned to the Internet as...
Read More