Blog
Not Your Grandmother's Fraud: How Data Quality is Measured in 2022

Everyone loves grandma. Grandma provides unconditional love, sage advice, and often good food. Grandma also reminds us of a time when the world moved at a different pace and things were a little less complicated. In grandma’s day, for instance, no one had to worry about data quality fraud in online surveys because online surveys didn’t exist!
Alas, that’s not the world we live in today.
Online fraud today is a big deal and a big threat to research validity. In this blog, we will tell you how much online survey fraud exists, how it is measured, and what you can do to avoid it.
How Much Survey Fraud Is There? What Effect Does It Have on the Validity of My Data?
No place may be more full of fraud than the internet. Consider that in addition to all the traditional scams—phishing attacks, Nigerian princes with an investment opportunity, debt elimination schemes—ransomware has become so lucrative in the last few years that criminal groups have adopted aspects of traditional business operations like customer support and brand management. It’s as if they want to say, “We’re bad guys, but we’re not really bad guys.”
Fraud within online surveys is far less common than online scams in general, but that doesn’t mean online survey fraud doesn’t occur.
Respondents in online surveys sometimes lie about their demographic information, use sophisticated tools to hide the location of their web traffic (when accessing studies from outside the host country), translate web pages into their native language (see below), auto fill multiple choice questions, and provide open-ended answers that are copied and pasted from the web rather than the thoughtful answers an engaged respondent would provide.
While it is extremely difficult to determine whether these behaviors are the product of individual bad actors or part of a coordinated criminal enterprise, what is not difficult is highlighting the threats they pose to data quality.
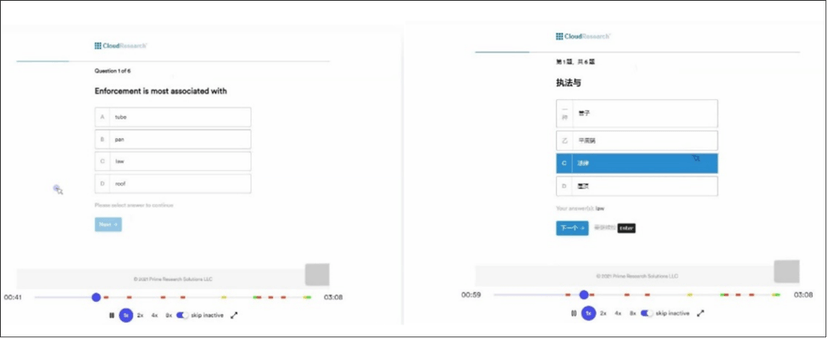
A respondent translates survey questions from English to Chinese within CloudResearch’s Sentry® vetting system. This respondent would be blocked from entering the survey.
Three Ways Online Participant Fraud Threatens Research
First, consider the scope of the problem. Across a variety of nonprobability panels, estimates suggest that 20-40% of respondents routinely fail even simple attention check questions.
When we look at the reasons why people fail CloudResearch’s Sentry® vetting system we get a clearer picture of online respondent behavior. For instance, during a period of two months in August and September 2021, just over 127,000 respondents from online panels failed our vetting measures and were blocked from entering CloudResearch studies.
Of these respondents, 40% were categorized as inattentive, 22% as yea-sayers, almost 9% were linked to duplicate IP addresses, 3.5% used technology to translate the language of the survey, and another 2% failed a CAPTCHA or location check. Several respondents failed for multiple reasons.
Second, consider the effect fraudulent respondents have when they are not screened out of studies. Random and nonsensical responses add noise to datasets, increase the odds of spurious findings, and add to study field times.
For concrete evidence of how fraudulent respondents add noise and produce spurious findings look no further than a report issued by the CDC in the early days of the COVID-19 outbreak. Using standard online panels and standard methods, the CDC estimated that almost 40% of Americans were engaging in dangerous cleaning practices to prevent COVID-19, including some very high-risk behaviors like washing food with bleach and gargling household cleaner.
The problem with these findings is that when CloudResearch replicated the study just as the CDC ran it—but with data quality vetting in place—we found that the most dangerous behaviors were almost entirely due to low-quality respondents.
People who failed our vetting measures by saying things like “I eat concrete for breakfast due to its iron content” also said they gargled bleach. You don’t have to stretch this example very far to see how these same people could ruin a brand awareness survey, a package testing study, or some similar study.
Finally, the third problem fraudulent respondents create is that they add substantially to study field times.
When research teams gather bad data, they have to spend time and effort checking survey responses and reconciling unusable respondents. Discarding large portions of data means that many projects end up having to go back into the field to top off sample sizes or even out quotas. These problems aren’t just an inconvenience; they also slow down research and decision making.
Given the threats posed by fraudulent respondents, you may be wondering: how can I eliminate fraud from my studies?
How To Address Survey Fraud
There are at least two ways to combat survey fraud. One way is for researchers and teams to include measures meant to detect fraud within the survey. The second method is to use data quality tools created by third parties.
On the side of individual action, research teams can add attention checks within surveys to flag inattentive and random responders. Teams may also add a system for flagging suspicious IP addresses and a process for evaluating the quality of open-ended responses. While these methods can help remove fraudulent respondents after the data are gathered, a more efficient approach may be to proactively keep fraudulent respondents out of surveys.
This is how the system developed by CloudResearch operates. With our patented Sentry technology, we combine industry standard technical checks with advanced technology like an event streamer that monitors respondents’ behavior and flags unnatural mouse movements or translation of webpage text into foreign languages. We also have respondents complete a few questions from a library of thousands of validated items to spot problems like yea-saying and inattention. Together, these processes identify and block problematic respondents before they enter your survey, improving data quality, saving the time required for reconciliation, and providing a baseline for data quality across panels.
No one can say for sure how threats to data quality will evolve in the future. What we can say, however, is that our team at CloudResearch will continue to inform researchers about these problems and develop the most innovative solutions to protect data quality. Just as today’s online environment isn’t a world most grandmas would recognize, the solutions of the future probably bear little resemblance to what works today.
Related Articles

Survey Screening Questions: Good & Bad Examples
Learn how to construct survey screening questions. We also demonstrate examples of good and bad survey screening questions....
Read More
The Truth About Online Data Quality: 30% of Survey Respondents Live on Pluto
Filtering through bad data in hopes to preserve the validity of online research can threaten your project, and just be plain time-consuming....
Read More