Blog
Online Research Changes, But CloudResearch Consistently Delivers The Highest Quality Data at the Lowest Price

By Aaron J. Moss, PhD, Rachel Hartman, PhD, & Leib Litman, PhD
Fans of 1990’s country music may recall Tracy Lawrence’s “Time Marches On.” As the chorus peaks, Lawrence sings, “The only thing that stays the same is everything changes, everything changes.”
In the world of online research, change happens fast. Even though the industry is only about 20 years old, some experts argue that online research is entering its third generation. Whereas generations one and two were focused on understanding if online data could be gathered and how to maintain data quality, the third generation is focused on where researchers can consistently gather quality data at an affordable price.
At CloudResearch, we’ve written a lot about the first two generations of online research. Our blogs and papers are filled with details about sampling and data quality. In this blog, we review several studies that are a part of the third generation of online research. Collectively, these independent studies consistently point to the benefits of using CloudResearch for online participant recruitment.
The Highest Quality Data at the Lowest Prices
There are many ways to measure data quality and to compare participant recruitment platforms. One approach is to integrate what’s in the published literature with survey data that asks researchers about their perceptions of different sources of online data. That is what researchers at Ohio State University and Providence College did in a forthcoming chapter.
In the chapter, the authors reviewed recent developments with online data collection and presented guidelines for transparent and responsible research. Near the end of the review, the researchers summarized what is known about multiple participant recruitment sites, presenting their findings in a large table.
What this table shows is that the papers in the published record show CloudResearch has the highest quality data at the lowest price. While the authors note that there is little published data on some of the platforms included in the table, both the CloudResearch MTurk Toolkit and Prime Panels platform were found to have excellent data quality and low costs (learn more about CloudResearch products).
If an integrative review is one way to assess data quality another is to dig into how participants respond within surveys. That is the approach taken in a recent paper by several economists at the University of Pittsburgh.
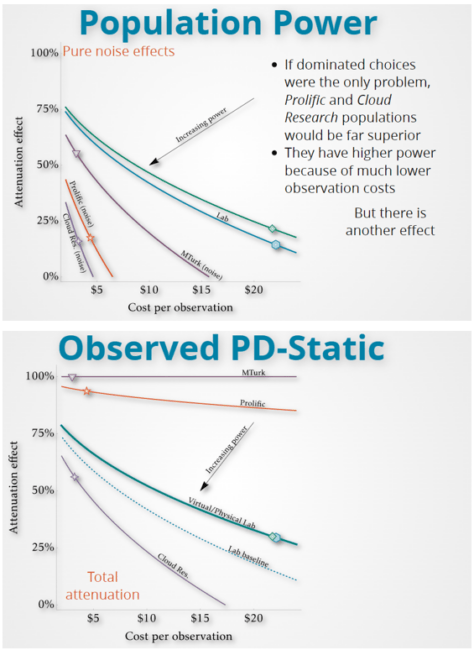
In this paper, the researchers wanted to understand how behavioral scientists should think about sampling when operating on a budget and knowing the population they are sampling from has some noise. Both noise and budget matter because they affect the power of statistical tests.
Participants in the study were asked to complete different economic games (e.g, the Prisoner’s Dilemma). From participants’ answers, the researchers examined how noisy the data were, how much power there was to test for statistical effects, and ultimately which platform delivered the best value (highest data quality at the lowest price). Any guesses who came out on top?
Consistent with the integrative review of past work, CloudResearch data was found to have little noise (i.e., it was high-quality) and to cost less than other sources. In fact, the cost of sampling from CloudResearch’s MTurk Toolkit was so low that even though the CloudResearch sample produced a slightly smaller effect size than an in-person sample, the low cost more than made up for the difference because researchers could gather more observations.
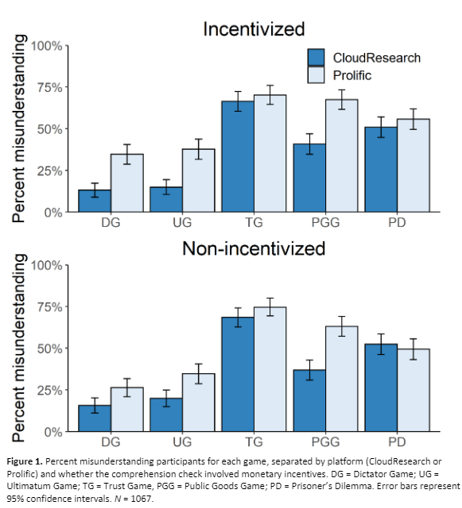
Remaining in the realm of economics, a third paper from researchers at Linköping University, the Stockholm School of Economics, and Western Norway University of Applied Sciences investigated how well participants comprehend the instructions from various economic games. Although there were many factors of interest to the researchers, one factor was participants’ comprehension of task instructions.
As displayed below, participants from CloudResearch showed greater comprehension than participants from Prolific. Even though it’s unclear what level of comprehension participants should show in this task—the researchers were testing whether features of the task are confusing to participants—and fairness requires us to point out that language issues may lower comprehension on Prolific (the CloudResearch sample was drawn from the US where nearly all participants are presumably native speakers of English while the Prolific sample was from a range of countries in Europe and North America where English is more likely a second language), the study demonstrates the ability of CloudResearch participants to read and comprehend task instructions, a behavior that is important in all online research.
Thus, to summarize, an integrative review of the published literature and two detailed analyses of participant responses within economic games all point to the same outcome: among the sites commonly used by behavioral scientists for online research, CloudResearch offers the highest quality data at the lowest costs.
Other Publications Highlighting the Value of CloudResearch
In addition to the publications above, there have recently been several papers whose stated goal was to compare data quality across platforms. While these comparisons can be informative, it’s important to remember that platforms have different strengths and weaknesses. Not all platforms operate the same way or are intended for the same purpose.
A major distinction is between crowdsourcing sites and market research panels. Crowdsourcing sites are generally smaller (100K-200K participants/year), offer researchers more flexibility, and have very engaged participants. Market research panels, however, are exponentially larger (tens of millions of participants/year), excel at demographic targeting, but generally have lower participant engagement. This means that managing data quality on market research panels requires more planning and more effort. Keeping this distinction in mind is important when evaluating the studies presented below.
In one recent comparison study, a team of researchers at Colorado State University, Villanova University, and the University of Arkansas, compared data quality across crowdsourced and professional market research panels. To do so, they replicated an advertising experiment and examined markers of data quality like participant satisficing, effort, attention, and multitasking. The study included samples from both the CloudResearch Approved participants on MTurk and Prime Panels among other sources.
Once again, the CloudResearch Approved participants provided the highest data quality. These participants showed little satisficing, a low amount of multitasking, and gave good effort in the study—passing attention checks, manipulation checks, and other measures of quality.
The participants from Prime Panels didn’t reach the same high bar as the CloudResearch Approved participants, but they still provided high quality data. More importantly, participants from Prime Panels cost a lot less than the other professional market research panels.
The lower cost of Prime Panels is largely due to its nature as a self-service tool researchers can use to set up and manage online studies. Other market research panels typically offer a managed research service where researchers must pay the company gathering data to help facilitate the project. Offering a DIY online tool allows CloudResearch to provide access to these samples at a lower cost than competing sites.

Perhaps an even stronger endorsement of our approach to data quality is contained in another recent comparison paper from authors at the Hebrew University of Jerusalem, Microsoft Research, and Prolific. In this study, the researchers compared data quality when platforms perform participant level vetting—as CloudResearch does—versus when researchers rely solely on within survey measures of data quality.
The results showed that platform vetting outperformed within-survey data quality checks on every measure in the study, including:
- Participant attention
- Honesty in a task where participants could cheat to earn more money
- Reliability scores
- The representativeness of participant demographics
- Effect sizes on well-replicated psychological effects
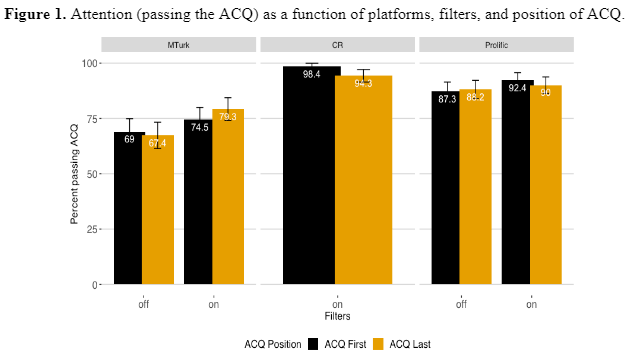
In other words, participant vetting by the platform was better than trying to flag poor-quality data on the fly.
Finally, another recent paper published in PLOS ONE by researchers from the University of Wisconsin-Madison and Kenyon University compared data quality from five sources. All five sources are commonly used by experimental psychologists and the measures of data quality included in the study were the types of things experimentalists care about: pass rates on attention checks, following instructions, remembering information presented previously in the study, and working slowly enough to read all items.
On the objective measures of data quality in the study (i.e., not participants’ own reports of data quality), CloudResearch Approved participants on MTurk performed better than MTurk alone, better than Qualtrics, and better than a student sample while essentially tying with Prolific. Among the three paid participant recruitment sites with quality data—CloudResearch, Prolific, and Qualtrics—CloudResearch cost the least.
How Does CloudResearch Consistently Deliver the Highest Quality Data at the Lowest Prices?
CloudResearch consistently provides high data quality across different products and situations because our team understands online data quality better than anyone else.
Over the last several years, our dedicated team of expert researchers—all with PhDs in experimental psychology—have conducted extensive surveys and experiments to identify the threats to data quality. We’ve also interviewed people engaged in survey fraud (see image below) and worked to understand their methods and habits.

After gathering this knowledge, we invested years in developing measures to identify and block people who provide poor quality data. We also worked to ensure our measures remove fraud and other problems without skewing the demographics of who researchers can sample.
After participants pass through our vetting measures, we actively review and monitor their data. We also update our criteria on a regular basis to address emerging threats to data quality. The result of this work is the high quality data found each time our tools have been tested.
As for what our services cost, the evidence of our affordability is demonstrated in the published papers reviewed above. Simply put, we charge less and deliver more.
Conclusion
Even though most studies that examine CloudResearch data quality do so by testing the MTurk Toolkit, the measures we use to vet participants are the same across products. In fact, our Sentry system is the backbone of all CloudResearch data quality. We’ve published peer-reviewed journal articles demonstrating the effectiveness of our vetting process (here and here).
So you can expect the same great results when using our Connect platform and the highest quality data among market research panels when using Prime Panels.
There are a lot of places to gather data from online research participants. In test after test and study after study, CloudResearch consistently sits at the top in both quality and value. We’re pretty proud of that.
Check out our Ultimate Guide to Survey Data Quality or schedule a demo to see how CloudResearch works!
Related Articles

Examples of Good (and Bad) Attention Check Questions in Surveys
Attention check questions are a valuable tool for ensuring data quality in surveys, but only if done right. See specific examples of good (and bad) attention checks here....
Read More
How Can You Get High-Quality Data from Amazon's Mechanical Turk? With CloudResearch's Approved Participants!
Humans have used information about other people's reputations for tens of thousands if not hundreds of thousands of years. Given people's fluency with tracking others' reputations it is not surprising...
Read More