Blog
Are Large Language Models a Large Research Problem?

Ever since ChatGPT 3 made its entrance in November 2022, it has been used for a diverse array of tasks, from creating meal plans and vacation itineraries to troubleshooting code. ChatGPT is just one popular example of a Large Language Model (LLM); others include Google’s Bard and Claude. LLMs are advanced AI programs trained to understand and generate human-like text based on vast amounts of data. They can answer open-ended text questions, write in various styles, and assist with a wide range of tasks by analyzing patterns in the text they were trained on. But behavioral scientists have been concerned about the ways that LLMs may impact research. While data quality has long been an issue in survey research, using open-ended questions to identify poor respondents was typically highly effective at improving data quality. Now, there’s a growing concern that survey participants might be employing ChatGPT to provide these answers, allowing them to easily bypass the open-ended safety measures. One preprint even estimated the usage of AI in survey research at nearly 50%.
The Problems with Using Large-Language Models in Surveys
On the CloudResearch research team, we suspected that some participants might use ChatGPT without fully grasping the implications for the research. While it might be a given for the researchers, participants might not always recognize the undesirability of AI-generated responses. Some could even view using AI as a means to enhance the quality of their written contribution to the study. After all, LLMs generate high-quality, well-written answers in a fraction of the time it might take a human to write a typo-riddled response.
Nevertheless, LLMs are not what most researchers want to survey in their studies. LLMs have many limitations. Most cannot access information that isn’t part of their training data (such as recent news events), they often miss nuanced context, and they can provide false information. Especially for researchers who study human behavior, the responses generated by LLMs won’t reflect the genuine diversity of human experiences that the researchers wish to capture. This isn’t to say that there isn’t a place for LLMs as part of research studies, but often that’s not what the researcher is looking for.
How to mitigate LLM usage in surveys: An Experiment with Connect Participants
To investigate this, we gave the same survey to three different groups on Connect: one was simply asked to answer an open-ended set of questions, the second was explicitly told not to use ChatGPT or any AI, and a third was warned their responses would be rejected if they did use AI tools.
A significant challenge to getting any estimate is accurately detecting the use of ChatGPT or other LLMs. It’s very difficult to determine if a text was authored by a human or AI. Some researchers have ventured into developing custom algorithms or combining various techniques. In our research, we used a combination of ZeroGPT and Sentry®, acknowledging that neither of these methods is foolproof.
We found that:
Detected ChatGPT use was considerably less than what other studies have reported.
Merely telling participants not to use ChatGPT reduced usage somewhat but we found the greatest reduction in those told their work could be rejected. Only 1 person out of 100 used AI tools in the third condition.
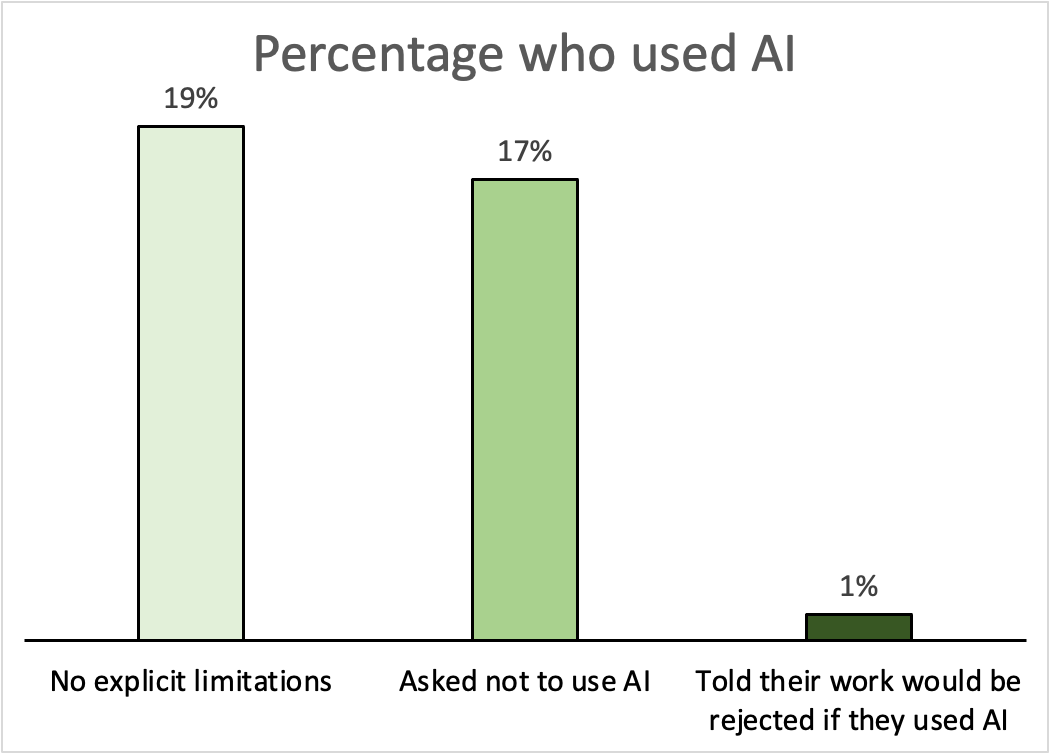
It’s also useful to adopt a practical perspective on this issue. Even if our detection mechanisms might have their limitations, we already know that Connect participants overwhelmingly offer high-quality data. This increases the likelihood that they’ll comply with guidelines and steer clear of AI tools when directed. In summary, explicit directions and penalties against using ChatGPT or other AI tools significantly curtail their usage, ensuring authentic human responses.
Related Articles

What's the Secret to CloudResearch's Data Quality? Sentry®
Learn more about Sentry, the secret to data quality across CloudResearch's products. Discover how Sentry improves online data quality from any sample source....
Read More
Connect by CloudResearch: Advancing Online Participant Recruitment in the Digital Age
Learn more about Connect's capabilities as well as the vision and dedication that drives its success in our new white paper....
Read More